Part 1: Single LLM Agents - The Promise and the Problem
Having established the fundamental tension between world knowledge and tool calling capabilities in Part 0, we now turn our attention to a predominant approach in today's AI landscape: single LLM agents. These systems represents the foundational block used to create a multi-agentic system, marking the staart of our distributed system construction process.
The Anatomy of a Single Agent
Modern single agents follow a deceptively simple architecture built around three core components that must work in perfect harmony:
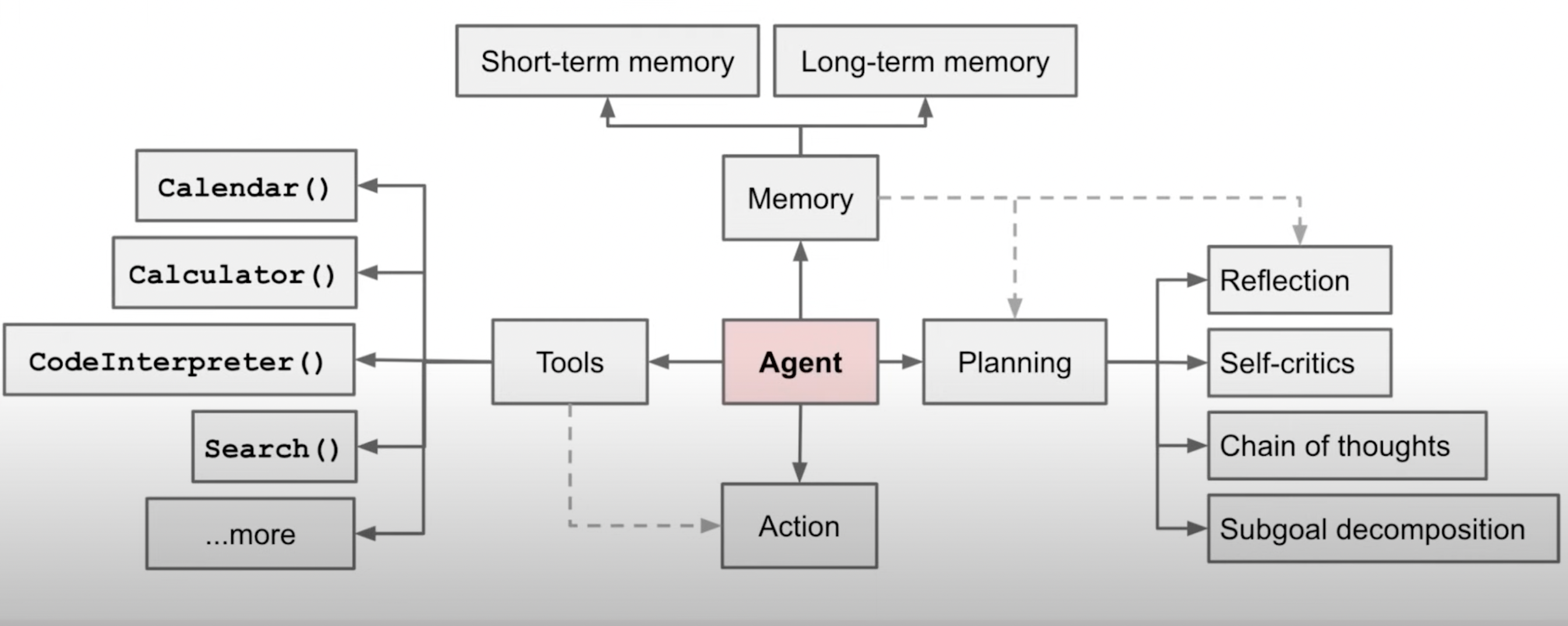
The Planning Engine
At the heart of every agent lies a planning system that decomposes complex requests into manageable steps. For example, when you ask it to "research competitors and write a market analysis," the agent must:
- Identify what information it needs
- Determine which tools can provide that information
- Sequence actions in logical order
- Adapt when plans encounter obstacles
- Maintain progress toward the ultimate goal
This planning happens dynamically—the agent doesn't script out every step upfront but makes moment-by-moment decisions about what to do next based on what it learns.
The Tool Orchestra
Single agents coordinate an impressive array of external capabilities: web search, databases, APIs, calculators, code interpreters, image generators, and specialized domain tools. The agent must:
- Select the right tool for each subtask
- Format requests appropriately for different systems
- Interpret responses and handle errors gracefully
- Synthesize information from multiple sources
- Manage API costs and rate limits
This orchestration layer transforms the LLM from an isolated text generator into a conductor directing an entire computational symphony.
The Memory Matrix
Agents maintain both working memory (tracking the current task) and long-term memory (learning from past interactions). This dual memory system enables:
- Contextual awareness: Remembering what happened earlier in the conversation
- Procedural learning: Improving at specific tasks through repetition
- Personalization: Adapting to individual users' preferences and patterns
- Error recovery: Learning from mistakes to avoid repeating them
The ReAct Revolution
The breakthrough that made practical agents possible came from the ReAct framework, which solved a critical chicken-and-egg problem in AI systems. Earlier approaches forced a choice: either pure reasoning (which couldn't access external information) or pure action (which couldn't plan effectively).
ReAct introduced a simple but powerful innovation: interleaving thinking and acting. Instead of planning everything upfront or acting blindly, agents now alternate between reasoning about what to do and taking actions based on that reasoning.
Consider how a ReAct agent handles "What's the current stock price of Tesla and how has it performed this quarter?"
Thought: I need to find Tesla's current stock price and quarterly performance data.
Action: Search for "Tesla stock price current TSLA"
Observation: Tesla (TSLA) is trading at $248.50, up 2.3% today...
Thought: I have the current price. Now I need quarterly performance data.
Action: Search for "Tesla stock performance Q3 2024 quarterly results"
Observation: Tesla reported Q3 earnings with revenue of $25.2B...
Thought: I can now provide a comprehensive answer combining both pieces of information.
This reasoning-action loop creates several advantages:
- Grounded thinking: Reasoning incorporates real-time data rather than relying solely on training knowledge
- Adaptive planning: Plans adjust based on what actions actually discover
- Error correction: The agent can recognize when actions don't produce expected results
- Transparency: Humans can follow the agent's reasoning process
When ReAct was evaluated across benchmarks from question-answering to complex decision-making tasks, it consistently outperformed both pure reasoning and pure action approaches—sometimes by margins of 30% or more.
The Cracks in the Foundation
Despite these architectural innovations, single agents encounter systematic limitations that trace directly back to the fundamental tension identified in Part 0. The very design that enables their versatility also constrains their effectiveness.
The Context Window Bottleneck: Every piece of information—task instructions, tool outputs, reasoning traces, and working memory—must squeeze through the same limited context window. As tasks grow complex, agents must constantly choose what to remember and what to forget.
The Capability Ceiling: A single model's parameters must encode both deep domain knowledge and tool-orchestration skills. Resources spent learning to call APIs are resources not spent understanding quantum physics, and vice versa.
The Reliability Valley: The more capabilities you add to a single system, the more points of failure you introduce. A single agent that can do 100 things will inevitably do some of them poorly, and users can't predict which ones will fail.
The Economic Reality: Running a frontier language model for every operation—from simple calculations to complex reasoning—creates unsustainable costs and latency for many applications.
These aren't implementation bugs to be fixed; they're fundamental trade-offs inherent in the single-agent architecture. Every token of context spent on tool orchestration is a token unavailable for deep reasoning. Every parameter tuned for API calling is a parameter not optimized for domain expertise.
The Stage is Set
Single LLM agents represent a remarkable achievement—systems that can genuinely reason, plan, and act across diverse domains. They've demonstrated that AI can move beyond static text generation to become dynamic problem-solving partners.
Yet their very success illuminates their limitations. The same architectural decisions that enable their versatility also constrain their ultimate capability. As we push these systems toward more complex, reliable, and cost-effective applications, we inevitably encounter the boundaries imposed by cramming everything into a single model.
This realization opens a compelling question: What if we stopped trying to build one superintelligent generalist and instead orchestrated multiple specialized agents, each optimized for specific aspects of the problem? What if the future of AI isn't about building bigger single agents, but about building smarter distributed systems?
Next in Part 2: We'll explore multi-agent architectures and how distributing capabilities across specialized agents can transcend the limitations we've identified in single-agent systems.